<dependencies> <!-- Spring Boot Web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
@SystemMessage(""" You are "MediBot", an AI medical assistant for Peking Union Medical College Hospital. Your responsibilities: 1. Provide general medical information and guidance 2. Help patients understand symptoms and treatment options 3. Assist with appointment scheduling when asked 4. Answer questions about hospital departments and doctors Rules: - Always be polite and professional - Include appropriate medical disclaimers - Never provide definitive diagnoses - Recommend seeing a doctor for serious concerns """) String chat(String userMessage); }
System Message is sent once at the start to set the AI’s behavior context.
5. Adding Chat Memory
5.1 Why Memory Matters
Without memory, each message is independent:
1 2 3 4 5
User: My name is John AI: Nice to meet you, John!
User: What's my name? AI: I don't know your name. ← Problem!
@SystemMessage("You are a helpful medical assistant.") String chat( @MemoryId Long conversationId, // Unique per conversation @UserMessage String message ); }
Function calling allows the LLM to invoke your Java methods. The LLM:
Analyzes the user’s request
Decides if a tool is needed
Extracts parameters
Calls your method
Uses the result in its response
1 2 3 4 5 6
User: Book an appointment with Dr. Wang tomorrow at 2pm
LLM → Detects "book appointment" intent → Calls bookAppointment(doctor="Dr. Wang", date="2025-06-12", time="14:00") ← Returns "Appointment confirmed" → Responds: "Your appointment with Dr. Wang is confirmed for tomorrow at 2pm."
6.2 Creating Tools
Annotate methods with @Tool:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
@Component publicclassCalculatorTools {
@Tool(name = "sum", value = "Add two numbers") publicdoublesum( @P(value = "First number")double a, @P(value = "Second number")double b) { return a + b; }
@Tool(name = "checkAvailability", value = "Check if a doctor has available slots") publicbooleancheckAvailability( @P(value = "Department name") String department, @P(value = "Date in YYYY-MM-DD format") String date, @P(value = "Time slot: morning or afternoon") String time, @P(value = "Doctor name (optional)", required = false) String doctorName) {
return appointmentService.hasAvailability(department, date, time, doctorName); }
@Tool(name = "bookAppointment", value = "Book a medical appointment. Confirm details with user first.") public String bookAppointment( @P(value = "Patient name") String patientName, @P(value = "Patient ID card number") String idCard, @P(value = "Department") String department, @P(value = "Date in YYYY-MM-DD") String date, @P(value = "Time: morning or afternoon") String time, @P(value = "Doctor name (optional)", required = false) String doctorName) {
You are "MediBot", an AI assistant for Peking Union Medical College Hospital.
Your capabilities: 1. Medical consultation - provide general health information 2. Department guidance - help patients find the right department 3. Doctor information - answer questions about our doctors 4. Appointment management - book and cancel appointments
Rules: - Always verify patient identity (name + ID card) before appointments - Confirm appointment details before booking - Use the knowledge base for hospital-specific information - Be professional yet friendly - Add appropriate emoji to make responses warm
@RestController @RequestMapping("/api/medical") @Tag(name = "Medical AI Assistant") publicclassMedicalController {
@Autowired private MedicalAssistant assistant;
@PostMapping("/chat") @Operation(summary = "Chat with medical assistant") public String chat(@RequestBody ChatRequest request) { return assistant.chat(request.getConversationId(), request.getMessage()); } }
@Data publicclassChatRequest { private Long conversationId; // Unique per user session private String message; }
9. Best Practices
System Design
Practice
Why It Matters
Use @MemoryId for multi-user
Prevents conversation bleeding between users
Persistent chat memory
Don’t lose context on server restart
Tool descriptions
Clear descriptions help LLM choose correctly
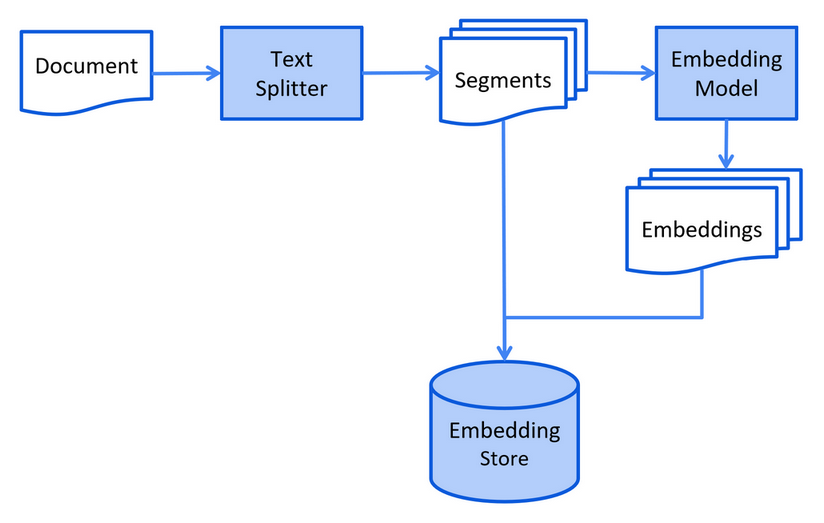
Document chunking
Smaller chunks improve retrieval precision
Min score threshold
Filters low-relevance results
Security
1 2
# Never commit API keys langchain4j.open-ai.chat-model.api-key=${OPENAI_API_KEY}
Performance
1 2 3 4 5 6 7 8
// Limit chat memory to control token usage MessageWindowChatMemory.withMaxMessages(10)
// Set minScore to filter irrelevant documents EmbeddingStoreContentRetriever.builder() .minScore(0.8) .maxResults(3) .build()
Common Pitfalls
Pitfall
Solution
LLM doesn’t use tools
Improve tool descriptions
Wrong tool parameters
Use @P annotations with clear descriptions
Out-of-scope responses
Refine system message
Slow responses
Use streaming output for real-time feedback
10. FAQ
Q: Can I switch from OpenAI to DeepSeek without code changes?
A: Yes. Just change the configuration:
1 2 3 4 5 6 7
# From OpenAI langchain4j.open-ai.chat-model.base-url=https://api.openai.com/v1 langchain4j.open-ai.chat-model.api-key=${OPENAI_KEY} # To DeepSeek langchain4j.open-ai.chat-model.base-url=https://api.deepseek.com langchain4j.open-ai.chat-model.api-key=${DEEPSEEK_KEY}
Q: How do I handle sensitive medical data?
A:
Use local LLMs via Ollama for sensitive data
Implement data anonymization before sending to external APIs
Store chat history encrypted
Follow HIPAA/GDPR compliance requirements
Q: What’s the difference between ChatMemory and ChatMemoryProvider?
A:
ChatMemory: Single shared memory instance
ChatMemoryProvider: Factory that creates isolated memory per memoryId
Q: How do I update the knowledge base?
A: Simply add new documents and re-ingest:
1 2 3 4 5
// New document DocumentnewDoc= FileSystemDocumentLoader.loadDocument("new-policy.md");
// Add to existing store EmbeddingStoreIngestor.ingest(newDoc, embeddingStore);
Q: Can the LLM call multiple tools in one conversation?
A: Yes. The LLM can chain tool calls:
1 2 3 4 5
User: "Book Dr. Wang and check if Dr. Li is available next week"
LLM → Calls bookAppointment(...) → Calls checkAvailability(...) → Responds with both results
11. Summary
We built a medical AI assistant using LangChain4J with:
Spring Boot Integration - Auto-configuration and dependency injection
LLM Integration - Unified API for OpenAI, DeepSeek, and others
Chat Memory - Persistent conversation context
Function Calling - Java methods callable by the LLM